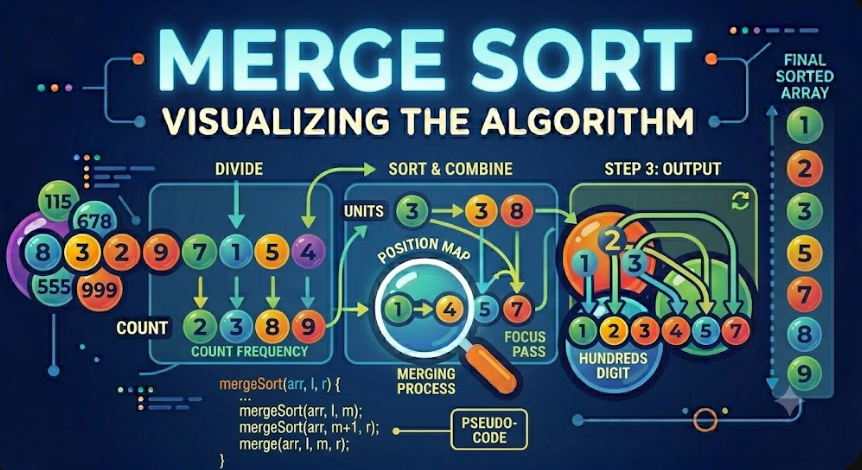
شرح خوارزمية الفرز بالدمج (Merge Sort)
الفرز بالدمج (Merge Sort) هي خوارزمية فرز قوية تعتمد على مبدأ "فرق تسد"، تقوم بفرز مصفوفة عن طريق تقسيمها إلى أجزاء أصغر، فرز تلك الأجزاء، ثم دمجها مرة أخرى بالترتيب الصحيح.
تعتبر خوارزمية الفرز بالدمج مهمة لأنها تضمن تعقيدًا زمنيًا يبلغ O(n log n) في أفضل الحالات، وفي الحالات المتوسطة، وفي أسوأ الحالات. وهذا يجعلها أكثر قابلية للتنبؤ من خوارزميات مثل Quicksort، التي يمكن أن تتدهور إلى O(n²) في أسوأ الحالات إذا كان اختيار المحور ضعيفًا.
مقدمة
الفرز هو إحدى أهم العمليات في علوم الحاسوب. يستخدم المطورون الفرز لتنظيم الأرقام، الأسماء، التواريخ، الأسعار، الدرجات، نتائج قواعد البيانات، الملفات، المنتجات، والعديد من أنواع البيانات الأخرى.
تعتبر خوارزميات الفرز البسيطة مثل Bubble Sort، و Selection Sort، و Insertion Sort مفيدة للتعلم، لكنها ليست فعالة لمجموعات البيانات الكبيرة لأن تعقيدها الزمني في الحالتين المتوسطة والأسوأ يكون عادة O(n²).
تقدم خوارزمية الفرز بالدمج طريقة تفكير أكثر كفاءة. بدلاً من مقارنة العناصر المتجاورة بشكل متكرر أو البحث عن أصغر قيمة، فإنها تقسم المصفوفة إلى مصفوفات أصغر، تفرزها بشكل تكراري، ثم تدمج الأجزاء المفرزة معًا مرة أخرى.
ما هو الفرز بالدمج (Merge Sort)؟
الفرز بالدمج هو خوارزمية فرز قائمة على المقارنة وتتبع استراتيجية "فرق تسد". تقوم بتقسيم مصفوفة الإدخال إلى نصفين، تفرز كل نصف بشكل تكراري، ثم تدمج النصفين المفرزين في مصفوفة مفرزة واحدة.
الفكرة الرئيسية بسيطة:
قسّم المصفوفة إلى نصفين.
استمر في تقسيم كل نصف حتى تحتوي كل مصفوفة فرعية على عنصر واحد.
المصفوفة ذات العنصر الواحد تكون مفرزة بالفعل.
اجمع المصفوفات المفرزة الصغيرة مرة أخرى.
استمر في الدمج حتى يتم فرز المصفوفة بأكملها.
تُسمى خوارزمية الفرز بالدمج بهذا الاسم لأن أهم عملية فيها هي دمج مصفوفتين مفرزتين في مصفوفة مفرزة أكبر.
مبدأ فرق تسد في الفرز بالدمج
الفرز بالدمج هو مثال كلاسيكي على مبدأ "فرق تسد". هذه الاستراتيجية تحل مشكلة كبيرة عن طريق تقسيمها إلى مشاكل أصغر من نفس النوع.
في الفرز بالدمج، يعمل مبدأ فرق تسد على النحو التالي:
التقسيم (Divide): قسّم المصفوفة إلى نصفين.
الفرز (Conquer): افرز كل نصف بشكل تكراري.
الدمج (Combine): ادمج النصفين المفرزين في مصفوفة مفرزة واحدة.
هذا الهيكل التكراري هو ما يسمح للفرز بالدمج بتحقيق أداء O(n log n).
لماذا يعتبر الفرز بالدمج مهمًا؟
الفرز بالدمج مهم لأنه يوفر أداءً موثوقًا. بغض النظر عن كيفية ترتيب مصفوفة الإدخال، لا يزال الفرز بالدمج يقسم المصفوفة بنفس الطريقة ويدمج القيم بشكل منهجي.
وهذا يجعل الفرز بالدمج مفيدًا لفهم ما يلي:
العودية (Recursion).
خوارزميات فرق تسد.
الفرز المستقر (Stable sorting).
أداء مضمون O(n log n).
الفرق بين الفرز في المكان (in-place) واستخدام ذاكرة إضافية.
الفرز بالدمج هو أيضًا أساس للعديد من الأفكار الخوارزمية المتقدمة ويتم مناقشته عادةً في دورات هياكل البيانات والخوارزميات.
كيف يعمل الفرز بالدمج؟
يعمل الفرز بالدمج على مرحلتين رئيسيتين: التقسيم والدمج.
خلال مرحلة التقسيم، تستمر الخوارزمية في تقسيم المصفوفة إلى نصفين حتى تحتوي كل مصفوفة فرعية على عنصر واحد فقط. العنصر الواحد يكون مفرزًا بالفعل بحكم التعريف.
خلال مرحلة الدمج، تجمع الخوارزمية مصفوفتين فرعيتين مفرزتين في مصفوفة مفرزة واحدة. تقارن العناصر الأولى لكلا المصفوفتين الفرعيتين وتأخذ القيمة الأصغر بشكل متكرر.
تستمر الخوارزمية في هذه العملية حتى يتم دمج جميع المصفوفات الفرعية مرة أخرى في مصفوفة واحدة مفرزة بالكامل.
مثال تشغيل يدوي
لنقم بفرز المصفوفة التالية يدويًا باستخدام الفرز بالدمج:
[8, 3, 5, 4, 7, 6, 1, 2]الهدف هو فرز المصفوفة بترتيب تصاعدي.
الخطوة 1: تقسيم المصفوفة
أولاً، يقسم الفرز بالدمج المصفوفة إلى نصفين:
[8, 3, 5, 4] [7, 6, 1, 2]ثم يُقسم كل نصف مرة أخرى:
[8, 3] [5, 4] [7, 6] [1, 2]ثم يُقسم كل زوج مرة أخرى حتى تحتوي كل مصفوفة فرعية على عنصر واحد:
[8] [3] [5] [4] [7] [6] [1] [2]عند هذه النقطة، تكون كل مصفوفة فرعية مفرزة لأن كل واحدة تحتوي على عنصر واحد فقط.
الخطوة 2: دمج العناصر الفردية
الآن تبدأ الخوارزمية في دمج المصفوفات ذات العنصر الواحد في أزواج مفرزة.
دمج [8] و [3]:
[8] + [3] = [3, 8]دمج [5] و [4]:
[5] + [4] = [4, 5]دمج [7] و [6]:
[7] + [6] = [6, 7]دمج [1] و [2]:
[1] + [2] = [1, 2]بعد مستوى الدمج الأول، لدينا:
[3, 8] [4, 5] [6, 7] [1, 2]الخطوة 3: دمج الأزواج المفرزة
الآن يقوم الفرز بالدمج بدمج الأزواج المفرزة.
دمج [3, 8] و [4, 5]:
Left: [3, 8]
Right: [4, 5]قارن القيم الأولى:
3 < 4, so take 3
8 > 4, so take 4
8 > 5, so take 5
Only 8 remains, so take 8النتيجة المدمجة هي:
[3, 4, 5, 8]الآن ادمج [6, 7] و [1, 2]:
Left: [6, 7]
Right: [1, 2]قارن القيم الأولى:
6 > 1, so take 1
6 > 2, so take 2
Only 6 and 7 remain, so take bothالنتيجة المدمجة هي:
[1, 2, 6, 7]بعد مستوى الدمج هذا، لدينا:
[3, 4, 5, 8] [1, 2, 6, 7]الخطوة 4: الدمج النهائي
الآن ندمج النصفين المفرزين:
Left: [3, 4, 5, 8]
Right: [1, 2, 6, 7]تعمل عملية الدمج خطوة بخطوة:
Compare 3 and 1 → take 1
Compare 3 and 2 → take 2
Compare 3 and 6 → take 3
Compare 4 and 6 → take 4
Compare 5 and 6 → take 5
Compare 8 and 6 → take 6
Compare 8 and 7 → take 7
Only 8 remains → take 8المصفوفة المفرزة النهائية هي:
[1, 2, 3, 4, 5, 6, 7, 8]المصفوفة المفرزة النهائية
[1, 2, 3, 4, 5, 6, 7, 8]يوضح هذا التشغيل اليدوي الفكرة الأساسية للفرز بالدمج. تقوم الخوارزمية أولاً بتقسيم المصفوفة إلى أجزاء صغيرة جدًا، ثم تبني النتيجة المفرزة عن طريق دمج تلك الأجزاء بالترتيب الصحيح.
شجرة العودية للفرز بالدمج
يمكن تصور الفرز بالدمج كشجرة عودية (recursion tree). تُقسم المصفوفة بشكل متكرر حتى يحتوي كل جزء على عنصر واحد.
[8, 3, 5, 4, 7, 6, 1, 2]
/ \
[8, 3, 5, 4] [7, 6, 1, 2]
/ \ / \
[8, 3] [5, 4] [7, 6] [1, 2]
/ \ / \ / \ / \
[8] [3] [5] [4] [7] [6] [1] [2]ثم تبني مرحلة الدمج المصفوفة المفرزة من الأسفل إلى الأعلى:
[8] [3] [5] [4] [7] [6] [1] [2]
\ / \ / \ / \ /
[3,8] [4,5] [6,7] [1,2]
\ / \ /
[3,4,5,8] [1,2,6,7]
\ /
[1,2,3,4,5,6,7,8]يشرح هيكل الشجرة هذا سبب وجود log n مستويات من العودية في الفرز بالدمج وسبب طلب كل مستوى لعملية دمج O(n).
شرح خطوة الدمج
خطوة الدمج هي جوهر الفرز بالدمج. تأخذ مصفوفتين مفرزتين وتجمعهما في مصفوفة مفرزة واحدة.
على سبيل المثال:
Left: [3, 8]
Right: [4, 5]كلا المصفوفتين مفرزتان بالفعل. تقارن دالة الدمج (merge function) أول قيمة متاحة في كل مصفوفة وتختار الأصغر.
العملية هي:
Compare 3 and 4 → take 3
Compare 8 and 4 → take 4
Compare 8 and 5 → take 5
Only 8 remains → take 8النتيجة هي:
[3, 4, 5, 8]يعمل هذا لأن كلا مصفوفتي الإدخال مفرزتان بالفعل. لا تحتاج دالة الدمج إلى مقارنة كل قيمة بكل قيمة أخرى.
خطوات خوارزمية الفرز بالدمج
يمكن وصف خوارزمية الفرز بالدمج باستخدام هذه الخطوات:
إذا كانت المصفوفة تحتوي على صفر أو عنصر واحد، فأعدها لأنها مفرزة بالفعل.
ابحث عن المؤشر الأوسط للمصفوفة.
قسّم المصفوفة إلى نصفين أيمن وأيسر.
طبق الفرز بالدمج بشكل تكراري على النصف الأيسر.
طبق الفرز بالدمج بشكل تكراري على النصف الأيمن.
ادمِج النصفين المفرزين.
أعد المصفوفة المفرزة المدمجة.
الحالة الأساسية (base case) مهمة. بدونها، لن تتوقف الاستدعاءات التكرارية أبدًا.
شفرة زائفة (Pseudocode)
mergeSort(array):
if length(array) <= 1:
return array
middle = length(array) / 2
left = mergeSort(first half of array)
right = mergeSort(second half of array)
return merge(left, right)يمكن وصف دالة الدمج على النحو التالي:
merge(left, right):
result = empty array
while left is not empty and right is not empty:
if first element of left <= first element of right:
move first element of left into result
else:
move first element of right into result
append remaining elements from left
append remaining elements from right
return resultتوضح هذه الشفرة الزائفة المنطق الرئيسي دون الاعتماد على لغة برمجة معينة.
مثال على الفرز بالدمج في PHP
فيما يلي تطبيق نظيف للفرز بالدمج بلغة PHP:
<?php
function mergeSort(array $numbers): array
{
$length = count($numbers);
if ($length <= 1) {
return $numbers;
}
$middle = intdiv($length, 2);
$left = array_slice($numbers, 0, $middle);
$right = array_slice($numbers, $middle);
return merge(
mergeSort($left),
mergeSort($right)
);
}
function merge(array $left, array $right): array
{
$result = [];
$i = 0;
$j = 0;
while ($i < count($left) && $j < count($right)) {
if ($left[$i] <= $right[$j]) {
$result[] = $left[$i];
$i++;
} else {
$result[] = $right[$j];
$j++;
}
}
while ($i < count($left)) {
$result[] = $left[$i];
$i++;
}
while ($j < count($right)) {
$result[] = $right[$j];
$j++;
}
return $result;
}
$numbers = [8, 3, 5, 4, 7, 6, 1, 2];
$sortedNumbers = mergeSort($numbers);
print_r($sortedNumbers);سيكون الإخراج:
Array
(
[0] => 1
[1] => 2
[2] => 3
[3] => 4
[4] => 5
[5] => 6
[6] => 7
[7] => 8
)هذا التنفيذ سهل القراءة. يستخدم array_slice لتقسيم المصفوفة ودالة منفصلة merge لدمج النصفين المفرزين.
مثال على الفرز بالدمج في JavaScript
فيما يلي نفس الخوارزمية مطبقة بلغة JavaScript:
function mergeSort(numbers) {
if (numbers.length <= 1) {
return numbers;
}
const middle = Math.floor(numbers.length / 2);
const left = numbers.slice(0, middle);
const right = numbers.slice(middle);
return merge(
mergeSort(left),
mergeSort(right)
);
}
function merge(left, right) {
const result = [];
let i = 0;
let j = 0;
while (i < left.length && j < right.length) {
if (left[i] <= right[j]) {
result.push(left[i]);
i++;
} else {
result.push(right[j]);
j++;
}
}
while (i < left.length) {
result.push(left[i]);
i++;
}
while (j < right.length) {
result.push(right[j]);
j++;
}
return result;
}
const numbers = [8, 3, 5, 4, 7, 6, 1, 2];
console.log(mergeSort(numbers));سيكون الإخراج:
[1, 2, 3, 4, 5, 6, 7, 8]تتبع نسخة JavaScript نفس منطق فرق تسد مثل نسخة PHP. تتغير الصيغة، لكن الفكرة الخوارزمية تبقى كما هي.
الفرز بالدمج مع السلاسل النصية (Strings)
يمكن أيضًا استخدام الفرز بالدمج لفرز السلاسل النصية أبجديًا. يعمل نفس منطق الدمج طالما يمكن مقارنة القيم.
Input:
['Lina', 'Ali', 'Omar', 'Sara']
Sorted:
['Ali', 'Lina', 'Omar', 'Sara']عند فرز السلاسل النصية، يجب على المطورين الانتباه إلى حساسية حالة الأحرف وقواعد اللغة المحلية. للتطبيقات الحقيقية، قد تتعامل دوال الفرز المدمجة بشكل أفضل مع هذه التفاصيل.
الفرز بالدمج مع الكائنات (Objects)
في مشاريع البرمجيات الحقيقية، غالبًا ما يفرز المطورون مصفوفات من الكائنات أو السجلات حسب حقل معين مثل السعر أو التاريخ أو الدرجة أو الاسم.
على سبيل المثال، يمكن فرز المنتجات حسب السعر:
<?php
function mergeProductsByPrice(array $left, array $right): array
{
$result = [];
$i = 0;
$j = 0;
while ($i < count($left) && $j < count($right)) {
if ($left[$i]['price'] <= $right[$j]['price']) {
$result[] = $left[$i];
$i++;
} else {
$result[] = $right[$j];
$j++;
}
}
return array_merge(
$result,
array_slice($left, $i),
array_slice($right, $j)
);
}يوضح هذا المثال أنه يمكن تكييف الفرز بالدمج لفرز هياكل البيانات المعقدة حسب حقل مخصص.
التعقيد الزمني لخوارزمية الفرز بالدمج
يصف التعقيد الزمني كيف يزداد وقت تشغيل الخوارزمية مع زيادة حجم الإدخال. يتميز الفرز بالدمج بتعقيد زمني يمكن التنبؤ به للغاية لأنه يقسم المصفوفة دائمًا إلى نصفين ويدمج النتائج.
يتميز الفرز بالدمج بالتعقيد الزمني التالي:
أفضل حالة: O(n log n)
متوسط الحالة: O(n log n)
أسوأ حالة: O(n log n)
هذا التناسق هو إحدى المزايا الرئيسية للفرز بالدمج.
لماذا الفرز بالدمج هو O(n log n)؟
يستمد الفرز بالدمج تعقيده O(n log n) من جزأين في الخوارزمية: التقسيم والدمج.
تُقسم المصفوفة إلى نصفين بشكل متكرر. عدد مستويات التقسيم هو تقريبًا log n.
n
n / 2
n / 4
n / 8
...
1في كل مستوى، يتم دمج جميع العناصر مرة واحدة. إجمالي عمل الدمج في كل مستوى هو O(n).
لذا يصبح إجمالي العمل:
O(n) work per level × O(log n) levels = O(n log n)لهذا السبب يعتبر الفرز بالدمج أكثر كفاءة بكثير من خوارزميات O(n²) لمجموعات البيانات الكبيرة.
التعقيد الزمني لأفضل حالة: O(n log n)
تحدث أفضل حالة عندما تكون المصفوفة مفرزة بالفعل.
[1, 2, 3, 4, 5, 6]حتى لو كانت المصفوفة مفرزة بالفعل، لا يزال الفرز بالدمج يقسمها إلى أجزاء أصغر ويدمج تلك الأجزاء مرة أخرى. لا يتوقف ببساطة بعد اكتشاف أن الإدخال مفرز.
لذلك، فإن التعقيد الزمني لأفضل حالة هو:
O(n log n)التعقيد الزمني للحالة المتوسطة: O(n log n)
تحدث الحالة المتوسطة عندما تكون المصفوفة بترتيب عشوائي.
[8, 3, 5, 4, 7, 6, 1, 2]لا يزال الفرز بالدمج يؤدي نفس هيكل التقسيم ونفس مستويات الدمج. لا يغير الترتيب الدقيق لقيم الإدخال بشكل كبير عدد المستويات أو كمية الدمج.
لذلك، فإن التعقيد الزمني للحالة المتوسطة هو:
O(n log n)التعقيد الزمني لأسوأ حالة: O(n log n)
أسوأ حالة لديها أيضًا تعقيد زمني O(n log n).
هذا يختلف عن Quicksort، حيث يمكن أن تؤدي اختيارات المحور السيئة إلى سلوك O(n²). لا يعتمد الفرز بالدمج على المحاور. إنه يقسم المصفوفة دائمًا إلى نصفين ويدمج الأجزاء المفرزة.
لذلك، فإن التعقيد الزمني لأسوأ حالة هو:
O(n log n)هذا الأداء المضمون يجعل الفرز بالدمج خوارزمية موثوقة.
التعقيد المكاني لخوارزمية الفرز بالدمج
يتطلب الفرز بالدمج عادةً ذاكرة إضافية لأنه ينشئ مصفوفات مؤقتة أثناء عملية الدمج.
التعقيد المكاني الشائع للفرز بالدمج هو:
O(n)تُستخدم هذه الذاكرة الإضافية لتخزين النتائج المدمجة. تستخدم الاستدعاءات التكرارية أيضًا ذاكرة المكدس، لكن التكلفة الرئيسية للذاكرة الإضافية تأتي من المصفوفات المؤقتة.
لهذا السبب، لا يُعتبر الفرز بالدمج عادةً خوارزمية فرز "في المكان" (in-place) في تطبيقها القياسي.
هل الفرز بالدمج مستقر؟
الفرز بالدمج مستقر عند تطبيقه بشكل صحيح.
الخوارزمية الفرز المستقرة تحافظ على الترتيب النسبي للعناصر المتساوية. على سبيل المثال، إذا كان منتجان لهما نفس السعر، فإن الفرز المستقر يبقيهما بنفس الترتيب الذي ظهرا به في القائمة الأصلية.
في الفرز بالدمج، يتم الحفاظ على الاستقرار أثناء خطوة الدمج إذا اختارت الخوارزمية العنصر الأيسر أولاً عندما تكون القيمتان متساويتين:
if left[i] <= right[j]:
take left[i]يساعد استخدام <= بدلاً من < فقط في الحفاظ على العناصر المتساوية في ترتيبها النسبي الأصلي.
هل الفرز بالدمج في المكان (In-Place)؟
الفرز بالدمج القياسي ليس في المكان لأنه يستخدم مصفوفات إضافية أثناء الدمج.
الخوارزمية في المكان تفرز البيانات دون الحاجة إلى ذاكرة إضافية كبيرة. يحتاج الفرز بالدمج عادةً إلى مساحة إضافية O(n)، لذلك لا يُعتبر في المكان في شكله الشائع.
هناك تقنيات دمج متقدمة في المكان، لكنها أكثر تعقيدًا ولا تُستخدم عادةً في التطبيقات الأولية.
الفرز بالدمج مقابل الفرز السريع (Quicksort)
كل من الفرز بالدمج والفرز السريع هما خوارزميتان فرز تعتمدان على مبدأ فرق تسد، لكن سلوكهما يختلف.
الاختلافات الرئيسية تشمل:
يقسم الفرز بالدمج المصفوفة إلى نصفين أولاً، ثم يدمج الأجزاء المفرزة.
يختار الفرز السريع محورًا ويقسم القيم حوله.
يتميز الفرز بالدمج بتعقيد زمني مضمون O(n log n).
يتميز الفرز السريع بمتوسط O(n log n)، ولكن أسوأ حالة O(n²).
الفرز بالدمج مستقر عند تطبيقه بشكل صحيح.
الفرز السريع عادة غير مستقر.
يحتاج الفرز بالدمج عادة إلى ذاكرة إضافية O(n).
يمكن غالبًا تنفيذ الفرز السريع بذاكرة إضافية أقل.
غالبًا ما يكون الفرز السريع أسرع في الممارسة للمصفوفات بسبب أداء ذاكرة التخزين المؤقت الجيد وعبء الذاكرة الأقل. يُفضل الفرز بالدمج عندما تكون الاستقرار والأداء المضمون أكثر أهمية.
الفرز بالدمج مقابل الفرز بالإدراج (Insertion Sort)
الفرز بالإدراج بسيط وفعال للمصفوفات الصغيرة أو شبه المفرزة. الفرز بالدمج أفضل لمجموعات البيانات الكبيرة لأن تعقيده الزمني هو O(n log n).
الاختلافات الرئيسية تشمل:
الفرز بالإدراج له أفضل حالة O(n)، ولكن متوسط وأسوأ حالة O(n²).
الفرز بالدمج له O(n log n) في جميع الحالات.
يستخدم الفرز بالإدراج ذاكرة إضافية O(1).
يستخدم الفرز بالدمج عادة ذاكرة إضافية O(n).
كلاهما يمكن أن يكون مستقرًا عند تطبيقهما بشكل صحيح.
تستخدم بعض أنظمة الفرز في العالم الحقيقي طرقًا هجينة، حيث تطبق الفرز بالدمج أو خوارزمية فعالة أخرى للبيانات الكبيرة وتتحول إلى الفرز بالإدراج للمصفوفات الفرعية الصغيرة جدًا.
الفرز بالدمج مقابل فرز الفقاعة (Bubble Sort) وفرز التحديد (Selection Sort)
فرز الفقاعة وفرز التحديد هما خوارزميتان بسيطتان، لكنهما غير فعالين لمجموعات البيانات الكبيرة. تعقيدهما الزمني في الحالتين المتوسطة والأسوأ هو O(n²).
الفرز بالدمج أكثر كفاءة بكثير للمدخلات الكبيرة لأنه يستخدم مبدأ فرق تسد.
Bubble Sort: O(n²)
Selection Sort: O(n²)
Merge Sort: O(n log n)لأغراض تعليمية، يعتبر فرز الفقاعة وفرز التحديد مفيدين لأنهما سهلا الفهم. بالنسبة للأداء، الفرز بالدمج أقوى بكثير.
متى يجب على المطورين استخدام الفرز بالدمج؟
يجب على المطورين النظر في استخدام الفرز بالدمج عندما يحتاجون إلى أداء يمكن التنبؤ به وفرز مستقر.
الفرز بالدمج مفيد عندما:
مجموعة البيانات كبيرة.
مطلوب أداء مضمون O(n log n).
الفرز المستقر مهم.
البيانات مخزنة في قائمة متصلة (linked list).
أداء أسوأ حالة يهم.
استخدام ذاكرة إضافية مقبول.
يعتبر الفرز بالدمج مناسبًا بشكل خاص عندما يكون الأداء المتسق أكثر أهمية من تقليل استخدام الذاكرة.
متى لا يجب استخدام الفرز بالدمج؟
قد لا يكون الفرز بالدمج هو الخيار الأفضل عندما تكون الذاكرة محدودة. لأنه يتطلب عادة مساحة إضافية O(n)، فقد يكون أقل ملاءمة للبيئات التي يجب أن يكون فيها استخدام الذاكرة منخفضًا جدًا.
قد يتجنب المطورون الفرز بالدمج عندما:
مجموعة البيانات صغيرة جدًا.
يجب أن يكون استخدام الذاكرة في حده الأدنى.
مطلوب فرز في المكان.
توفر لغة البرمجة بالفعل دالة فرز مدمجة محسنة للغاية.
في معظم تطبيقات الإنتاج، يجب على المطورين استخدام دوال الفرز المدمجة ما لم يكن لديهم سبب محدد لتنفيذ الفرز يدويًا.
مثال عملي: فرز أسعار المنتجات
تخيل نظام تجارة إلكترونية يحتاج إلى فرز أسعار المنتجات من الأقل إلى الأعلى. يمكن للفرز بالدمج فرز القائمة بشكل موثوق.
<?php
$prices = [99.99, 29.99, 49.99, 19.99, 79.99];
$sortedPrices = mergeSort($prices);
print_r($sortedPrices);ستكون النتيجة:
Array
(
[0] => 19.99
[1] => 29.99
[2] => 49.99
[3] => 79.99
[4] => 99.99
)هذا المثال بسيط، لكنه يربط الفرز بالدمج ببيانات التطبيق الحقيقية.
مثال عملي: فرز المنشورات حسب التاريخ
يمكن أيضًا استخدام الفرز بالدمج لفرز السجلات حسب التاريخ إذا كان منطق المقارنة يتحقق من حقل التاريخ.
على سبيل المثال، يمكن فرز منشورات المدونة من الأقدم إلى الأحدث أو العكس. ولأن الفرز بالدمج يمكن أن يكون مستقرًا، فإن المنشورات التي لها نفس التاريخ يمكن أن تحافظ على ترتيبها النسبي الأصلي.
يمكن أن يكون هذا الاستقرار مفيدًا عند فرز السجلات التي تحتوي على مفاتيح مكررة.
أخطاء شائعة عند تطبيق الفرز بالدمج
غالبًا ما يفهم المبتدئون الفكرة الرئيسية للفرز بالدمج ولكن يرتكبون أخطاء في التنفيذ التكراري أو في دالة الدمج.
تشمل الأخطاء الشائعة ما يلي:
نسيان الحالة الأساسية.
حساب المؤشر الأوسط بشكل غير صحيح.
عدم إرجاع النتيجة المدمجة.
فقدان العناصر المتبقية بعد استنفاد أحد الجانبين.
استخدام
<بدلاً من<=وفقدان الاستقرار.الخلط بين مرحلة التقسيم ومرحلة الدمج.
إنشاء العديد من النسخ غير الضرورية دون فهم تكلفة الذاكرة.
التفصيل الأكثر أهمية هو خطوة الدمج. إذا كانت دالة الدمج خاطئة، فستعيد الخوارزمية بأكملها نتائج غير صحيحة.
قائمة تحقق عملية لفهم الفرز بالدمج
قبل الانتقال إلى خوارزميات أكثر تقدمًا، يجب أن يكون المطورون قادرين على الإجابة على هذه الأسئلة:
ماذا يعني مبدأ فرق تسد؟
لماذا يقسم الفرز بالدمج المصفوفة إلى نصفين؟
ما هي الحالة الأساسية للفرز بالدمج؟
كيف تجمع دالة الدمج مصفوفتين مفرزتين؟
لماذا الفرز بالدمج هو O(n log n)؟
لماذا يحتاج الفرز بالدمج إلى مساحة إضافية O(n)؟
هل الفرز بالدمج مستقر؟
كيف يختلف الفرز بالدمج عن الفرز السريع (Quicksort)؟
إذا كانت هذه الأسئلة واضحة، فإن المطور يفهم المنطق الحقيقي وراء الفرز بالدمج بدلاً من مجرد حفظ الكود.
مزايا الفرز بالدمج
يتميز الفرز بالدمج بالعديد من المزايا المهمة.
لديه تعقيد زمني مضمون O(n log n).
مستقر عند تطبيقه بشكل صحيح.
يعمل بشكل جيد مع مجموعات البيانات الكبيرة.
يمكن التنبؤ بأدائه في أفضل الحالات، المتوسطة، والأسوأ.
هو مثال قوي على مبدأ فرق تسد.
يعمل بشكل جيد مع القوائم المتصلة (linked lists).
هذه المزايا تجعل الفرز بالدمج أحد أهم خوارزميات الفرز التي يجب تعلمها.
عيوب الفرز بالدمج
للفرز بالدمج أيضًا قيود.
يتطلب عادة ذاكرة إضافية O(n).
ليس عادة في المكان.
قد يكون أبطأ من الفرز السريع في الممارسة للمصفوفات بسبب عمليات الذاكرة الإضافية.
لديه عبء إضافي أكبر من الخوارزميات البسيطة للمصفوفات الصغيرة جدًا.
قد يكون التنفيذ التكراري أصعب على المبتدئين في البداية.
بسبب هذه القيود، ليس الفرز بالدمج دائمًا الخيار العملي الأفضل، على الرغم من أدائه النظري الممتاز.
الفرز بالدمج في مشاريع البرمجيات الحقيقية
تظهر مفاهيم الفرز بالدمج في العديد من أنظمة البرمجيات الحقيقية، خاصة عندما يكون الفرز المستقر والأداء المتوقع مهمين.
تستخدم بعض لغات البرمجة والمكتبات خوارزميات مستوحاة من الفرز بالدمج أو تجمع أفكار الفرز بالدمج مع تقنيات أخرى. على سبيل المثال، غالبًا ما تستخدم أنظمة الفرز المستقرة منطقًا قائمًا على الدمج لأن دمج التكرارات المفرزة موثوق به ويمكن التنبؤ به.
في تطبيقات الواجهة الخلفية (backend)، لا يقوم المطورون عادة بتنفيذ الفرز بالدمج يدويًا لمنطق العمل العادي. بدلاً من ذلك، يستخدمون دوال الفرز المدمجة أو ترتيب قاعدة البيانات. ومع ذلك، فإن فهم الفرز بالدمج يساعد المطورين على التفكير في الأداء، استخدام الذاكرة، الاستقرار، وتصميم الخوارزميات.
الخاتمة
الفرز بالدمج هو خوارزمية فرز تعتمد على مبدأ فرق تسد، حيث تقسم مصفوفة إلى أجزاء أصغر، تفرز تلك الأجزاء بشكل تكراري، ثم تدمجها مرة أخرى في مصفوفة مفرزة واحدة.
أكبر قوة لها هي الموثوقية. تتميز خوارزمية الفرز بالدمج بتعقيد زمني يبلغ O(n log n) في أفضل الحالات، وفي الحالات المتوسطة، وفي أسوأ الحالات. وهذا يجعلها أكثر قابلية للتنبؤ من الخوارزميات التي قد تصبح بطيئة اعتمادًا على ترتيب الإدخال.
الفرز بالدمج مستقر أيضًا عند تطبيقه بشكل صحيح، مما يجعله مفيدًا عندما يكون الترتيب النسبي للعناصر المتساوية مهمًا. ومع ذلك، فإنه يتطلب عادة ذاكرة إضافية O(n)، لذلك لا يُعتبر عادة خوارزمية فرز في المكان.
بالنسبة للمطورين الذين يتعلمون هياكل البيانات والخوارزميات، يُعد الفرز بالدمج خوارزمية أساسية. إنه يعلم العودية، ومبدأ فرق تسد، والدمج، والاستقرار، والتعقيد الزمني، والمفاضلة بين السرعة والذاكرة. فهم الفرز بالدمج يهيئ المطورين لدراسة خوارزميات أكثر تقدمًا ولاتخاذ قرارات أفضل عند اختيار استراتيجيات الفرز في مشاريع البرمجيات الحقيقية.

