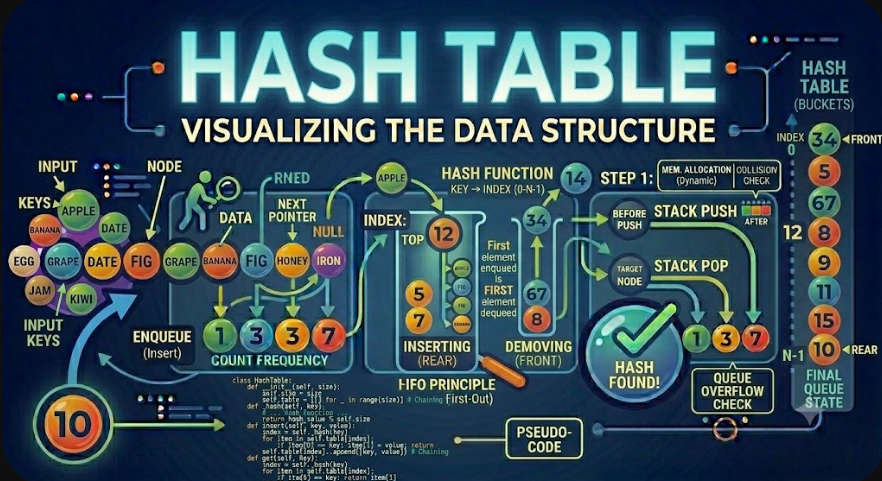
Hash Tabloları, Hash Kümeleri ve Hash Haritaları Açıklamalı
Hash Tablosu, bir hash fonksiyonu kullanarak veri depolayan bir veri yapısıdır. Anahtarları dahili bir dizideki konumlara eşleyerek ortalama O(1) zamanda hızlı ekleme, arama ve silme işlemlerine olanak tanır.
Hash Tabloları, Veri Yapıları ve Algoritmalar'daki en önemli konulardan biridir. Hash Kümeleri ve Hash Haritalarının temelini oluştururlar ve sözlükler, önbellekler, veritabanları, indeksler, derleyiciler, yönlendirme tabloları ve arama hizmetleri gibi birçok gerçek yazılım sisteminde bulunurlar.
Giriş
Geliştiricilerin verileri hızlı bir şekilde araması gerektiğinde, basit bir dizi her zaman yeterli olmaz. Dizi sıralı değilse, arama işlemi Doğrusal Arama (Linear Search) kullanarak her elemanı tek tek kontrol etmeyi gerektirebilir. Bu, O(n) zaman karmaşıklığı verir.
Hash Tabloları bu sorunu farklı bir fikirle çözer. Tüm elemanlar arasında arama yapmak yerine, bir Hash Tablosu verinin nereye depolanması gerektiğini hesaplamak için bir anahtar ve bir hash fonksiyonu kullanır.
Bu, ekleme, arama, güncelleme ve silme gibi birçok işlemin ortalama olarak çok hızlı olmasını sağlar. Bu nedenle, Hash Tabloları programlama dillerinde, framework'lerde, veritabanlarında ve gerçek dünyadaki arka uç sistemlerinde yoğun olarak kullanılır.
Hash Tablosu Nedir?
Hash Tablosu, bir hash fonksiyonu kullanarak verileri dizi benzeri bir yapıda depolayan bir veri yapısıdır. Hash fonksiyonu bir anahtarı bir indekse dönüştürür ve bu indeks değerin nereye depolanacağını belirler.
Temel fikir şöyledir:
key → hash function → index → bucketÖrneğin, bir kullanıcıyı e-posta ile depolamak istersek, e-posta anahtar olarak kullanılabilir:
Key: user@example.com
Value: User dataHash fonksiyonu anahtarı dahili bir dizi indeksine dönüştürür:
hash(user@example.com) % tableSize = 3Böylece değer, kova indeksi 3'e depolanır.
Hash Tabloları Neden Önemlidir?
Hash Tabloları çok hızlı arama sağladıkları için önemlidir. Birçok uygulamada, geliştiricilerin şu soruları yanıtlaması gerekir:
Bu kullanıcı adı zaten mevcut mu?
Bu ID hangi kullanıcıya ait?
Bu öğe zaten koleksiyonda mı?
Bu kelime kaç kez geçti?
Bu izin bu role atanmış mı?
Bu anahtarı kullanarak önbelleğe alınmış verileri alabilir miyiz?
Bir Hash Tablosu olmadan, bu işlemler bir listeyi taramayı gerektirebilir. Bir Hash Tablosu ile bunlar genellikle ortalama O(1) zamanda yapılabilir.
Hash Tablosu Terminolojisi
Hash Tablolarını derinlemesine incelemeden önce, yaygın terimleri anlamak önemlidir.
Anahtar (Key): Veriyi depolamak veya almak için kullanılan tanımlayıcı.
Değer (Value): Bir anahtarla ilişkili gerçek veri.
Hash fonksiyonu (Hash function): Bir anahtarı sayısal bir hash değerine dönüştüren bir fonksiyon.
İndeks (Index): Verinin depolanabileceği dahili dizideki konum.
Kova (Bucket): Dahili dizideki bir yuva.
Çakışma (Collision): İki farklı anahtarın aynı indeksi üretmesi durumu.
Yük faktörü (Load factor): Hash tablosunun ne kadar dolu olduğunun bir ölçüsü.
Yeniden hashleme (Rehashing): Tabloyu yeniden boyutlandırma ve anahtarları yeniden dağıtma süreci.
Bu terimler neredeyse her Hash Tablosu uygulamasında karşımıza çıkar.
Hash Tablosu Nasıl Çalışır?
Bir Hash Tablosu genellikle üç ana adımda çalışır.
Bir anahtar bir hash fonksiyonuna iletilir.
Hash fonksiyonu sayısal bir hash değeri üretir.
Hash değeri bir dizi indeksine dönüştürülür.
Örneğin:
Key: "apple"
Hash function output: 93029210
Table size: 10
Index = 93029210 % 10 = 0apple anahtarıyla ilişkili değer, 0 numaralı kovaya depolanır.
Daha sonra değeri almak istediğimizde, aynı anahtar aynı hash fonksiyonuna iletilir. Bu aynı indeksi üretir, böylece Hash Tablosu nereye bakacağını bilir.
Hash Fonksiyonu Nedir?
Hash fonksiyonu, bir girdi anahtarını alan ve onu sayısal bir değere dönüştüren bir fonksiyondur. Bu sayısal değer daha sonra dahili dizide bir indeks hesaplamak için kullanılır.
İyi bir hash fonksiyonu şunları yapmalıdır:
Aynı anahtar için her zaman aynı hash değerini döndürmelidir.
Anahtarları tablo boyunca eşit şekilde dağıtmalıdır.
Hızlı hesaplanmalıdır.
Çakışmaları mümkün olduğunca azaltmalıdır.
Eğitim amaçlı olarak, karakterleri sayılara dönüştüren basit bir hash fonksiyonu hayal edebiliriz.
Basit Hash Fonksiyonu Örneği
Şu anahtara sahip olduğumuzu varsayalım:
catHer karakteri sayısal bir koda dönüştürüp bunları toplayabiliriz:
c = 99
a = 97
t = 116
hash = 99 + 97 + 116 = 312Tablo boyutu 10 ise, indeks şöyle olur:
index = 312 % 10 = 2Böylece cat anahtarı 2 numaralı kovaya depolanır.
Bu hash fonksiyonu basit ve öğrenmek için kullanışlıdır, ancak gerçek hash fonksiyonları daha iyi dağılım ve daha az çakışma gerektirdiği için daha gelişmiştir.
Bellekte Hash Tablosu
Bir Hash Tablosu genellikle dahili bir kova dizisi kullanır. Her kova, bir anahtar-değer çifti veya çakışmalar meydana gelirse bir anahtar-değer çiftleri koleksiyonu depolayabilir.
Örneğin:
Index 0: empty
Index 1: empty
Index 2: key = cat, value = 5
Index 3: empty
Index 4: key = dog, value = 8Tablo, öğeleri eklendikleri sıraya göre depolamaz. Onları hash indeksine göre depolar.
Bu nedenle Hash Tabloları arama için mükemmeldir ancak belirli dil uygulaması ekleme sırasını korumadıkça sıralı geçiş için tasarlanmamıştır.
Manuel Çalıştırma Örneği
Küçük bir Hash Tablosuna üç anahtar-değer çiftini manuel olarak ekleyelim.
Table size = 5Basit bir eğitim amaçlı hash fonksiyonu kullanacağız:
hash(key) = sum of character codes
index = hash(key) % tableSizeEklemek istediklerimiz:
"cat" → 10
"dog" → 20
"bird" → 30Adım 1: 'cat' Ekle
cat için hash değerini hesaplayın:
c = 99
a = 97
t = 116
hash = 99 + 97 + 116 = 312İndeksi hesaplayın:
index = 312 % 5 = 2Değeri 2 numaralı indekse depolayın:
Index 0: empty
Index 1: empty
Index 2: cat → 10
Index 3: empty
Index 4: emptyAdım 2: 'dog' Ekle
dog için hash değerini hesaplayın:
d = 100
o = 111
g = 103
hash = 100 + 111 + 103 = 314İndeksi hesaplayın:
index = 314 % 5 = 4Değeri 4 numaralı indekse depolayın:
Index 0: empty
Index 1: empty
Index 2: cat → 10
Index 3: empty
Index 4: dog → 20Adım 3: 'bird' Ekle
bird için hash değerini hesaplayın:
b = 98
i = 105
r = 114
d = 100
hash = 98 + 105 + 114 + 100 = 417İndeksi hesaplayın:
index = 417 % 5 = 22 numaralı indeks zaten cat değerini içeriyor. Bu bir çakışma (collision) yaratır.
Index 2 already has:
cat → 10
New item:
bird → 30Hash Tablosu bu çakışmayı bir çakışma çözümleme stratejisi kullanarak ele almalıdır.
Çakışma Nedir?
Bir çakışma, iki farklı anahtarın Hash Tablosunda aynı indeksi üretmesi durumunda meydana gelir.
Örneğin:
cat → index 2
bird → index 2Her iki anahtar da aynı kovayı kullanmak istiyor. Hash Tablolarında çakışmalar normaldir çünkü birçok olası anahtar sınırlı sayıda kovaya eşlenir.
İyi bir Hash Tablosu çakışmaları imkansız hale getirmeye çalışmaz. Bunun yerine, onları doğru bir şekilde ele almak için bir strateji kullanır.
Çakışma Yönetimi Stratejileri
En yaygın iki çakışma yönetimi stratejisi şunlardır:
Ayrı zincirleme (Separate chaining).
Açık adresleme (Open addressing).
Her strateji çakışmaları farklı bir şekilde çözer.
Ayrı Zincirleme
Ayrı zincirleme, her kovanın genellikle bağlı liste veya dinamik dizi içinde birden çok anahtar-değer çifti depolayabileceği anlamına gelir.
Eğer hem cat hem de bird 2 numaralı indekse eşleniyorsa, kova ikisini de depolayabilir:
Index 0: empty
Index 1: empty
Index 2: [cat → 10] → [bird → 30]
Index 3: empty
Index 4: dog → 202 numaralı indekste bir anahtar ararken, Hash Tablosu eşleşen anahtarı bulana kadar o kovadaki öğeleri kontrol eder.
Ayrı zincirleme, anlaşılması kolay olduğu için eğitim amaçlı açıklamalarda basit ve yaygındır.
Açık Adresleme
Açık adresleme, tüm anahtar-değer çiftlerini doğrudan ana dizinin içinde depolar. Bir çakışma meydana gelirse, Hash Tablosu başka bir boş kova arar.
Örneğin, 2 numaralı indeks zaten kullanılıyorsa, tablo 3 numaralı indeksi deneyebilir:
Index 0: empty
Index 1: empty
Index 2: cat → 10
Index 3: bird → 30
Index 4: dog → 20Açık adresleme için farklı yoklama (probing) yöntemleri vardır:
Doğrusal yoklama (Linear probing): Boş bir kova bulunana kadar bir sonraki indeksi, sonra bir sonrakini deneyin.
Karesel yoklama (Quadratic probing): Kümelenmeyi azaltmak için karesel bir adım deseni kullanın.
Çift hashleme (Double hashing): Yoklama adımını belirlemek için ikinci bir hash fonksiyonu kullanın.
Açık adresleme bellek açısından verimli olabilir, ancak silinen girişlerin ve tablo yeniden boyutlandırmanın dikkatli bir şekilde ele alınmasını gerektirir.
Yük Faktörü
Yük faktörü, Hash Tablosunun ne kadar dolu olduğunu ölçer.
load factor = number of stored items / number of bucketsÖrneğin, bir tablonun 10 kovası varsa ve 7 öğe depoluyorsa:
load factor = 7 / 10 = 0.7Yüksek yük faktörü, tablonun dolmakta olduğu anlamına gelir. Bu, çakışmaları artırabilir ve performansı düşürebilir.
Birçok Hash Tablosu uygulaması, yük faktörü çok yükseldiğinde tabloyu yeniden boyutlandırır.
Yeniden Hashleme (Rehashing)
Yeniden hashleme, daha büyük bir Hash Tablosu oluşturma ve mevcut tüm öğeleri ona taşıma sürecidir.
Buna ihtiyaç duyulur çünkü tablo çok dolduğunda çakışmalar artar. Daha büyük bir tablo, hash fonksiyonuna anahtarları dağıtmak için daha fazla kova konumu verir.
Yeniden hashleme sırasında:
Yeni, daha büyük bir kova dizisi oluşturulur.
Mevcut her anahtar yeniden hashlenir.
Her anahtar-değer çifti yeni tabloya eklenir.
Eski tablo değiştirilir.
Yeniden hashleme zaman maliyetlidir, ancak her işlemde gerçekleşmez. Ortalama işlemleri O(1)'e yakın tutmaya yardımcı olur.
Hash Tablosu İşlemleri
Bir Hash Tablosu genellikle şu işlemleri destekler:
ekle (insert): Bir anahtar-değer çifti ekleyin.
al (get): Bir anahtarla bir değeri alın.
güncelle (update): Bir anahtarla ilişkili değeri değiştirin.
sil (delete): Bir anahtar-değer çiftini kaldırın.
içerir mi (contains): Bir anahtarın mevcut olup olmadığını kontrol edin.
anahtarlar (keys): Tüm anahtarları döndürün.
değerler (values): Tüm değerleri döndürün.
En önemli avantajı, ekleme, alma, silme ve içerme işlemlerinin ortalama O(1) olmasıdır.
Hash Tablosu Sözde Kodu
class HashTable:
buckets = array of empty lists
hash(key):
return numeric hash value
index(key):
return hash(key) % bucket count
set(key, value):
i = index(key)
if key exists in buckets[i]:
update value
else:
add key-value pair to buckets[i]
get(key):
i = index(key)
search buckets[i] for key
if found:
return value
return null
delete(key):
i = index(key)
remove key-value pair from buckets[i]Bu sözde kod, çakışma yönetimi için ayrı zincirleme kullanır.
PHP'de Hash Tablosu Örneği
İşte ayrı zincirleme kullanan PHP'de basit bir eğitim amaçlı Hash Tablosu uygulaması.
<?php
class SimpleHashTable
{
private array $buckets;
public function __construct(private int $size = 10)
{
$this->buckets = array_fill(0, $this->size, []);
}
private function hash(string $key): int
{
$hash = 0;
for ($i = 0; $i < strlen($key); $i++) {
$hash += ord($key[$i]);
}
return $hash;
}
private function index(string $key): int
{
return $this->hash($key) % $this->size;
}
public function set(string $key, mixed $value): void
{
$index = $this->index($key);
foreach ($this->buckets[$index] as &$pair) {
if ($pair['key'] === $key) {
$pair['value'] = $value;
return;
}
}
$this->buckets[$index][] = [
'key' => $key,
'value' => $value,
];
}
public function get(string $key): mixed
{
$index = $this->index($key);
foreach ($this->buckets[$index] as $pair) {
if ($pair['key'] === $key) {
return $pair['value'];
}
}
return null;
}
public function contains(string $key): bool
{
return $this->get($key) !== null;
}
public function delete(string $key): bool
{
$index = $this->index($key);
foreach ($this->buckets[$index] as $position => $pair) {
if ($pair['key'] === $key) {
unset($this->buckets[$index][$position]);
$this->buckets[$index] = array_values($this->buckets[$index]);
return true;
}
}
return false;
}
}
$table = new SimpleHashTable();
$table->set('name', 'Adnan');
$table->set('role', 'Developer');
echo $table->get('name'); // Adnan
echo PHP_EOL;
var_dump($table->contains('role')); // true
$table->delete('role');
var_dump($table->contains('role')); // falseBu uygulama öğrenme amacıyla basitleştirilmiştir. Gerçek dil düzeyindeki hash tabloları çok daha optimize edilmiş olup birçok köşe durumunu ele alır.
JavaScript'te Hash Tablosu Örneği
İşte ayrı zincirleme kullanan JavaScript'te basit bir Hash Tablosu uygulaması.
class SimpleHashTable {
constructor(size = 10) {
this.size = size;
this.buckets = Array.from({ length: size }, () => []);
}
hash(key) {
let hash = 0;
for (const char of key) {
hash += char.charCodeAt(0);
}
return hash;
}
index(key) {
return this.hash(key) % this.size;
}
set(key, value) {
const index = this.index(key);
const bucket = this.buckets[index];
for (const pair of bucket) {
if (pair.key === key) {
pair.value = value;
return;
}
}
bucket.push({ key, value });
}
get(key) {
const index = this.index(key);
const bucket = this.buckets[index];
for (const pair of bucket) {
if (pair.key === key) {
return pair.value;
}
}
return null;
}
contains(key) {
return this.get(key) !== null;
}
delete(key) {
const index = this.index(key);
const bucket = this.buckets[index];
for (let i = 0; i < bucket.length; i++) {
if (bucket[i].key === key) {
bucket.splice(i, 1);
return true;
}
}
return false;
}
}
const table = new SimpleHashTable();
table.set('name', 'Adnan');
table.set('role', 'Developer');
console.log(table.get('name')); // Adnan
console.log(table.contains('role')); // true
table.delete('role');
console.log(table.contains('role')); // falseJavaScript versiyonu PHP versiyonuyla aynı konsepti takip eder. Anahtarlar kova indekslerine dönüştürülür ve çakışmalar kovaların içindeki diziler kullanılarak ele alınır.
Yerleşik Dillerde Hash Tabloları
Birçok programlama dili, yerleşik Hash Tablosu benzeri yapılar sağlar.
Örnekler şunlardır:
PHP: İlişkisel diziler (Associative arrays).
JavaScript: Objects, Map ve Set.
Python: dict ve set.
Java: HashMap ve HashSet.
C#: Dictionary ve HashSet.
Bu yerleşik yapılar genellikle optimize edilmiştir ve sıfırdan manuel olarak bir Hash Tablosu uygulamak yerine gerçek projelerde kullanılmalıdır.
DSA Hash Kümeleri
Hash Kümesi, benzersiz değerleri depolayan bir veri yapısıdır. Genellikle bir Hash Tablosunun üzerine inşa edilir, ancak anahtar-değer çiftleri yerine yalnızca anahtarları depolar.
Bir Hash Kümesinin temel amacı şu soruyu hızlı bir şekilde yanıtlamaktır:
Does this value exist?Örneğin:
Hash Set:
{apple, banana, orange}banana değerini tekrar eklemeye çalışırsak, küme bir kopyasını depolamaz.
{apple, banana, orange}Bu, Hash Kümelerini benzersizlik ve üyelik kontrolü için kullanışlı kılar.
Hash Kümesi İşlemleri
Bir Hash Kümesi genellikle şu işlemleri destekler:
ekle (add): Henüz mevcut değilse bir değer ekleyin.
sahip mi (has): Bir değerin mevcut olup olmadığını kontrol edin.
sil (delete): Bir değeri kaldırın.
boyut (size): Benzersiz değerlerin sayısını döndürün.
temizle (clear): Tüm değerleri kaldırın.
Ekleme, sahip olma ve silme işlemlerinin ortalama zaman karmaşıklığı O(1)'dir.
Hash Kümesi için Manuel Çalıştırma
Bu Hash Kümesi işlemlerini manuel olarak çalıştıralım:
add(10)
add(20)
add(10)
has(20)
delete(10)
has(10)Boş bir küme ile başlayın:
{}add(10) işleminden sonra:
{10}add(20) işleminden sonra:
{10, 20}add(10) işlemi tekrar yapıldıktan sonra:
{10, 20}10 değeri tekrarlanmaz.
Şimdi has(20) şunları döndürür:
truedelete(10) işleminden sonra:
{20}Şimdi has(10) şunları döndürür:
falseBu manuel çalıştırma, bir Hash Kümesinin ana davranışını gösterir: benzersiz depolama ve hızlı üyelik kontrolü.
JavaScript'te Hash Kümesi Örneği
JavaScript, yerleşik bir Set nesnesi sağlar.
const visitedUsers = new Set();
visitedUsers.add(101);
visitedUsers.add(102);
visitedUsers.add(101);
console.log(visitedUsers.has(101)); // true
console.log(visitedUsers.size); // 2
visitedUsers.delete(101);
console.log(visitedUsers.has(101)); // false101 değeri sadece bir kez eklenir çünkü Kümeler (Sets) benzersiz değerleri depolar.
PHP'de Hash Kümesi Örneği
PHP'nin JavaScript'teki gibi özel bir yerleşik Set türü yoktur, ancak ilişkisel diziler (associative arrays) bir Hash Kümesini simüle etmek için kullanılabilir.
<?php
$visitedUsers = [];
$visitedUsers[101] = true;
$visitedUsers[102] = true;
$visitedUsers[101] = true;
var_dump(isset($visitedUsers[101])); // true
echo count($visitedUsers); // 2
unset($visitedUsers[101]);
var_dump(isset($visitedUsers[101])); // falseAnahtarlar küme değerlerini temsil eder. Dizi anahtarları benzersiz olduğundan, tekrarlar doğal olarak önlenir.
Hash Kümelerinin Yaygın Kullanım Durumları
Hash Kümeleri, benzersizlik veya üyelik kontrolü önemli olduğunda kullanışlıdır.
Yaygın kullanım durumları şunlardır:
Tekrarlayan değerleri kaldırma.
Bir öğenin zaten ziyaret edilip edilmediğini kontrol etme.
Tekrarlayan kullanıcı adlarını veya e-postaları tespit etme.
Graf algoritmalarında ziyaret edilen düğümleri takip etme.
Bir değerin bir koleksiyonda mevcut olup olmadığını kontrol etme.
Koleksiyonlar arasındaki kesişimleri bulma.
Örneğin, graf geçişinde, bir Hash Kümesi ziyaret edilen düğümleri depolayabilir, böylece algoritma aynı düğümü iki kez işlemez.
Örnek: Hash Kümesi Kullanarak Tekrarları Kaldırma
Şu diziye sahip olduğumuzu varsayalım:
[3, 5, 3, 2, 5, 1]Bir Hash Kümesi kullanarak, yalnızca benzersiz değerleri saklayabiliriz:
{3, 5, 2, 1}JavaScript'te:
const numbers = [3, 5, 3, 2, 5, 1];
const uniqueNumbers = [...new Set(numbers)];
console.log(uniqueNumbers);Çıktı şöyle olacaktır:
[3, 5, 2, 1]Sıra, JavaScript'in Set'inde ekleme sırasını takip edebilir, ancak ana fikir benzersizliktir.
DSA Hash Haritaları
Hash Haritası, anahtar-değer çiftlerini depolayan bir veri yapısıdır. Genellikle bir Hash Tablosunun üzerine inşa edilir.
Bir Hash Haritasının temel amacı şu soruyu hızlı bir şekilde yanıtlamaktır:
What value belongs to this key?Örneğin:
userId → userName
101 → Ali
102 → Sara
103 → Omar102 anahtarını biliyorsak, Sara değerini hızlıca alabiliriz.
Hash Haritası İşlemleri
Bir Hash Haritası genellikle şu işlemleri destekler:
ayarla (set): Bir anahtar-değer çifti ekleyin veya güncelleyin.
al (get): Bir anahtar için değeri alın.
sahip mi (has): Bir anahtarın mevcut olup olmadığını kontrol edin.
sil (delete): Bir anahtar-değer çiftini kaldırın.
anahtarlar (keys): Tüm anahtarları döndürün.
değerler (values): Tüm değerleri döndürün.
girişler (entries): Tüm anahtar-değer çiftlerini döndürün.
Ayarlama, alma, sahip olma ve silme işlemlerinin ortalama zaman karmaşıklığı O(1)'dir.
Hash Haritası için Manuel Çalıştırma
Bu Hash Haritası işlemlerini manuel olarak çalıştıralım:
set('name', 'Ali')
set('age', 25)
get('name')
set('age', 26)
delete('name')
has('name')Boş bir harita ile başlayın:
{}set('name', 'Ali') işleminden sonra:
{
name: Ali
}set('age', 25) işleminden sonra:
{
name: Ali,
age: 25
}get('name') şunları döndürür:
Aliset('age', 26) işleminden sonra, değer güncellenir:
{
name: Ali,
age: 26
}delete('name') işleminden sonra:
{
age: 26
}has('name') şunları döndürür:
falseBu manuel çalıştırma, bir Hash Haritasının anahtar-değer davranışını gösterir.
JavaScript'te Hash Haritası Örneği
JavaScript, yerleşik bir Map nesnesi sağlar.
const userMap = new Map();
userMap.set(101, 'Ali');
userMap.set(102, 'Sara');
userMap.set(103, 'Omar');
console.log(userMap.get(102)); // Sara
console.log(userMap.has(101)); // true
userMap.set(102, 'Sarah');
console.log(userMap.get(102)); // Sarah
userMap.delete(101);
console.log(userMap.has(101)); // falseMap, değerleri anahtarla depolar ve hızlı aramaya izin verir.
PHP'de Hash Haritası Örneği
PHP ilişkisel dizileri (associative arrays) yaygın olarak Hash Haritaları olarak kullanılır.
<?php
$userMap = [];
$userMap[101] = 'Ali';
$userMap[102] = 'Sara';
$userMap[103] = 'Omar';
echo $userMap[102]; // Sara
echo PHP_EOL;
var_dump(isset($userMap[101])); // true
$userMap[102] = 'Sarah';
echo $userMap[102]; // Sarah
echo PHP_EOL;
unset($userMap[101]);
var_dump(isset($userMap[101])); // falseBu, PHP geliştiricilerinin gerçek projelerde Hash Haritası davranışını kullandığı en yaygın yollardan biridir.
Hash Tablosu vs Hash Kümesi vs Hash Haritası
Hash Tablosu, Hash Kümesi ve Hash Haritası yakından ilişkilidir, ancak tam olarak aynı kavram değildir.
Hash Tablosu, temel veri yapısı fikridir. Bir hash fonksiyonu, kovalar ve çakışma yönetimi kullanır.
Hash Kümesi benzersiz değerleri depolar. Dahili olarak, değerlerin anahtar gibi davrandığı bir Hash Tablosu kullanabilir.
Hash Haritası anahtar-değer çiftlerini depolar. Dahili olarak, değerlerin nereye depolandığını hesaplamak için anahtarları kullanır.
Hash Table: underlying mechanism
Hash Set: stores unique values
Hash Map: stores key-value pairsBasit terimlerle:
Sadece bir değerin var olup olmadığını önemsediğinizde bir Hash Kümesi kullanın.
Değerleri anahtarla depolamanız ve almanız gerektiğinde bir Hash Haritası kullanın.
Her iki yapının dahili olarak nasıl çalıştığını anlamak için Hash Tablolarını inceleyin.
Hash Tablolarının Zaman Karmaşıklığı
Zaman karmaşıklığı, giriş boyutu arttıkça işlemlerin çalışma süresinin nasıl büyüdüğünü açıklar.
Hash Tabloları için yaygın ortalama karmaşıklıklar şunlardır:
Ekleme: Ortalama O(1)
Arama: Ortalama O(1)
Silme: Ortalama O(1)
Güncelleme: Ortalama O(1)
Geçiş: O(n)
Ortalama O(1) performansı, Hash Tablolarının bu kadar kullanışlı olmasının ana nedenidir.
En Kötü Durum Zaman Karmaşıklığı
Hash Tablosu işlemlerinin en kötü durumu O(n) olabilir.
Bu, birçok anahtarın aynı kovada çakışması durumunda meydana gelir. Tüm anahtarlar tek bir kovada depolanırsa, Hash Tablosunun o kovanın içindeki birçok öğeyi taraması gerekebilir.
Index 0: empty
Index 1: empty
Index 2: [key1] → [key2] → [key3] → [key4] → [key5]
Index 3: emptyHedef anahtar zincirin sonundaysa, arama O(n) zaman alabilir.
İyi hash fonksiyonları, yeniden boyutlandırma ve çakışma yönetimi pratikte bu durumdan kaçınmaya yardımcı olur.
Hash Tablolarının Alan Karmaşıklığı
Bir Hash Tablosunun alan karmaşıklığı genellikle O(n)'dir, burada n depolanan öğe sayısıdır.
Ancak, Hash Tabloları aynı zamanda kovalar da tahsis eder ve bazı kovalar boş olabilir. Bu, basit bir listeden daha fazla bellek kullanabilecekleri anlamına gelir.
Bellek maliyeti şunları içerir:
Kova dizisi.
Depolanan anahtarlar.
Depolanan değerler.
Çakışmalar için ekstra referanslar veya zincir yapıları.
Hash Tabloları, daha hızlı arama için ek bellek kullanır.
Hash Tabloları Neden Ortalama O(1)'dir?
Hash Tabloları ortalama O(1)'dir çünkü hash fonksiyonu bir anahtarın nereye depolanması gerektiğini doğrudan hesaplar.
Öğeleri tek tek kontrol etmek yerine, tablo şunu yapar:
key → hash → indexÇakışmalar azsa, kova yalnızca bir veya birkaç öğe içerir. Bu, aramayı çok hızlı hale getirir.
Ancak, O(1) her durumda garanti edilmez. İyi hashleme, makul yük faktörü ve etkili çakışma yönetimine bağlıdır.
Pratik Örnek: Kelime Sıklığı Sayma
Hash Haritaları sıklıkları saymak için mükemmeldir.
Şu kelime listesine sahip olduğumuzu varsayalım:
apple, banana, apple, orange, banana, appleOluşumları saymak için bir Hash Haritası kullanabiliriz:
apple → 3
banana → 2
orange → 1JavaScript'te:
const words = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple'];
const frequency = new Map();
for (const word of words) {
const currentCount = frequency.get(word) || 0;
frequency.set(word, currentCount + 1);
}
console.log(frequency);Her kelime hızlı bir şekilde güncellenebildiği için bu, klasik bir Hash Haritası kullanım durumudur.
Pratik Örnek: Tekrarları Tespit Etme
Hash Kümeleri tekrarları tespit etmek için mükemmeldir.
Şu diziye sahip olduğumuzu varsayalım:
[4, 2, 7, 4, 9]Diziyi tarayabilir ve küme içine değerler ekleyebiliriz. Kümede zaten mevcut olan bir değer görürsek, bir tekrar bulmuş oluruz.
const numbers = [4, 2, 7, 4, 9];
const seen = new Set();
for (const number of numbers) {
if (seen.has(number)) {
console.log('Duplicate found:', number);
break;
}
seen.add(number);
}Bu, iç içe döngüleri önler ve performansı O(n²)'den ortalama O(n)'ye iyileştirir.
Pratik Örnek: İki Toplam Problemi
İki Toplam problemi, bir Hash Haritasının performansı artırdığı ünlü bir örnektir.
Bir dizi ve bir hedef verildiğinde, hedefe ulaşan iki sayıyı bulun.
numbers = [2, 7, 11, 15]
target = 9Cevap 2 ve 7'dir.
Bir Hash Haritası kullanarak, daha önce gördüğümüz sayıları depolarız:
function twoSum(numbers, target) {
const seen = new Map();
for (let i = 0; i < numbers.length; i++) {
const complement = target - numbers[i];
if (seen.has(complement)) {
return [seen.get(complement), i];
}
seen.set(numbers[i], i);
}
return [];
}
console.log(twoSum([2, 7, 11, 15], 9));Çıktı şöyle olacaktır:
[0, 1]Bu çözüm ortalama O(n)'dir, çünkü Hash Haritasındaki her arama ortalama O(1)'dir.
Geliştiriciler Ne Zaman Hash Kümesi Kullanmalı?
Geliştiriciler, benzersizlik veya hızlı üyelik kontrolü gerektiğinde bir Hash Kümesi kullanmalıdır.
Hash Kümeleri şu durumlarda kullanışlıdır:
Tekrarlayan değerler kaldırılmalıdır.
Ziyaret edilen öğeler takip edilmelidir.
Üyelik kontrolleri sık sık yapılmalıdır.
Yalnızca değerler önemlidir, anahtar-değer ilişkileri değil.
Graf geçişi ziyaret edilen bir koleksiyona ihtiyaç duyar.
Ana soru şudur: Sadece bir değerin var olup olmadığını bilmemiz mi gerekiyor? Cevap evet ise, bir Hash Kümesi doğru seçim olabilir.
Geliştiriciler Ne Zaman Hash Haritası Kullanmalı?
Geliştiriciler, anahtarları değerlerle ilişkilendirmeleri gerektiğinde bir Hash Haritası kullanmalıdır.
Hash Haritaları şu durumlarda kullanışlıdır:
Kullanıcı ID'lerinin kullanıcı verilerine eşlenmesi gerekir.
Ürün kodlarının ürün nesnelerine eşlenmesi gerekir.
Kelimelerin sayımlara eşlenmesi gerekir.
Önbellek anahtarlarının önbelleğe alınmış sonuçlara eşlenmesi gerekir.
Yapılandırma adlarının değerlere eşlenmesi gerekir.
Anahtara göre hızlı arama gereklidir.
Ana soru şudur: Bir anahtar kullanarak bir değer almamız mı gerekiyor? Cevap evet ise, bir Hash Haritası genellikle güçlü bir seçimdir.
Hash Tabloları Ne Zaman Kullanılmamalı?
Hash Tabloları güçlüdür, ancak her zaman en iyi seçim değildir.
Geliştiriciler şu durumlarda Hash Tablolarından kaçınabilir:
Sıralı düzen gereklidir.
Aralık sorguları gereklidir.
Bellek kullanımı minimum olmalıdır.
Anahtarların doğru bir şekilde hashlenmesi zordur.
Öngörülebilir iterasyon sırası gereklidir ve dil bunu garanti etmez.
En kötü durum garantileri, ortalama performanstan daha önemlidir.
Sıralı veriler için ağaçlar veya sıralı diziler daha iyi olabilir. Aralık sorguları için dengeli ağaçlar veya veritabanı indeksleri daha uygun olabilir.
Hash Tabloları vs Diziler
Diziler ve Hash Tabloları farklı sorunları çözer.
Diziler, elemanlara sayısal indeksle erişildiğinde iyidir.
array[0]
array[1]
array[2]Hash Tabloları, değerlere anahtarla erişildiğinde iyidir.
users['email@example.com']
products['SKU-100']Başlıca farklılıklar şunlardır:
Diziler, indekse göre hızlı erişim sağlar.
Hash Tabloları, anahtara göre hızlı erişim sağlar.
Diziler doğal indeks sırasını korur.
Hash Tabloları verileri hash indekslerine göre düzenler.
Diziler basit ve bellek açısından verimlidir.
Hash Tabloları hızlı arama için ek bellek kullanır.
Veriler doğal olarak konuma göre indeksleniyorsa, bir dizi kullanın. Verilere anahtarla erişiliyorsa, bir Hash Haritası veya Hash Tablosu kullanın.
Hash Tabloları vs İkili Arama
İkili Arama (Binary Search) sıralı diziler üzerinde çalışır ve O(log n) zaman karmaşıklığına sahiptir. Hash Tabloları genellikle ortalama O(1) arama sağlar.
Ancak, İkili Arama verileri sıralı tutarken, Hash Tabloları doğal olarak sıralı düzeni desteklemez.
Başlıca farklılıklar şunlardır:
İkili Arama sıralı veri gerektirir.
Hash Tabloları sıralı veri gerektirmez.
İkili Arama araması O(log n)'dir.
Hash Tablosu araması ortalama O(1)'dir.
İkili Arama sıralı mantığı destekler.
Hash Tabloları doğrudan anahtar araması için daha iyidir.
Doğru seçim, sıranın önemli olup olmadığına bağlıdır.
Hash Tablolarını Öğrenirken Yapılan Yaygın Hatalar
Yeni başlayanlar genellikle Hash Tablolarının her zaman O(1) olduğunu düşünür, ancak bu sadece ortalama durum davranışıdır.
Yaygın hatalar şunlardır:
Çakışmaları göz ardı etmek.
Çakışmaların imkansız olduğunu düşünmek.
Kötü bir hash fonksiyonu kullanmak.
Tekrarlayan anahtarları ele almayı unutmak.
Hash Kümesini Hash Haritası ile karıştırmak.
Hash Tablolarının her zaman sırayı koruduğunu varsaymak.
Bellek yükünü göz ardı etmek.
Sıralı düzen gerektiğinde Hash Tabloları kullanmak.
En önemli nokta, Hash Tablolarının iyi hashleme ve çakışma yönetimi sayesinde güçlü olmasıdır.
Hash Tablolarını Anlamak İçin Pratik Kontrol Listesi
Daha ileri konulara geçmeden önce, geliştiriciler şu soruları yanıtlayabilmelidir:
Anahtar nedir?
Değer nedir?
Hash fonksiyonu ne işe yarar?
Bir hash değeri nasıl indekse dönüştürülür?
Kova nedir?
Çakışma nedir?
Ayrı zincirleme nasıl çalışır?
Açık adresleme nedir?
Yük faktörü nedir?
İşlemler neden ortalama O(1)'dir?
En kötü durum neden O(n) olabilir?
Hash Kümesi ile Hash Haritası arasındaki fark nedir?
Bu sorular netleştiğinde, geliştirici sadece terminolojiyi ezberlemek yerine Hash Tablolarını derinlemesine anlamış olur.
Hash Tablolarının Avantajları
Hash Tablolarının birkaç önemli avantajı vardır.
Ortalama O(1) ekleme sağlarlar.
Ortalama O(1) arama sağlarlar.
Ortalama O(1) silme sağlarlar.
Anahtar-değer depolaması için mükemmeldirler.
Benzersizlik kontrolleri için kullanışlıdırlar.
Önbellekleme ve indeksleme için pratiktirler.
Birçok algoritmayı O(n²)'den O(n)'ye iyileştirirler.
Bu avantajlar, Hash Tablolarını yazılım geliştirmedeki en kullanışlı veri yapılarından biri yapar.
Hash Tablolarının Dezavantajları
Hash Tablolarının sınırlamaları da vardır.
Ek bellek kullanırlar.
Doğal olarak sıralı düzeni korumazlar.
En kötü durum işlemleri O(n) olabilir.
Performans hash fonksiyonuna bağlıdır.
Çakışma yönetimi karmaşıklık ekler.
Yeniden hashleme gerçekleştiğinde maliyetli olabilir.
Bu sınırlamalar Hash Tablolarını kötü yapmaz. Sadece başka bir veri yapısının ne zaman daha uygun olabileceğini gösterirler.
Gerçek Yazılım Projelerinde Hash Tabloları
Hash Tabloları gerçek yazılım projelerinde her yerde karşımıza çıkar.
Yaygın gerçek dünya kullanımları şunlardır:
ID veya e-postaya göre kullanıcı arama.
SKU'ya göre ürün arama.
Anahtara göre önbellek depolama.
Oturum depolama.
Sıklıkları sayma.
Tekrarları kaldırma.
Ziyaret edilen düğümleri takip etme.
Veritabanı indeksleme kavramları.
Derleyici sembol tabloları.
Yönlendirme tabloları ve yapılandırma haritaları.
Arka uç geliştiricileri için Hash Haritaları ve Hash Kümeleri özellikle önemlidir çünkü veri işleme, doğrulama, önbellekleme ve API mantığında yer alırlar.
Sonuç
Hash Tablosu, anahtarları dahili dizi indekslerine eşlemek için bir hash fonksiyonu kullanan bir veri yapısıdır. Ortalama O(1) zamanda hızlı ekleme, arama, güncelleme ve silme işlemlerine olanak tanır.
Hash Tabloları, Hash Kümeleri ve Hash Haritalarının temelini oluşturur. Bir Hash Kümesi benzersiz değerleri depolar ve üyelik kontrolü için kullanışlıdır. Bir Hash Haritası anahtar-değer çiftlerini depolar ve anahtarla hızlı arama için kullanışlıdır.
En önemli dahili kavramlar hash fonksiyonları, kovalar, çakışmalar, çakışma yönetimi, yük faktörü ve yeniden hashlemedir. Bu kavramlar, Hash Tablolarının neden ortalama olarak hızlı olduğunu ve en kötü durum performanslarının neden O(n) olabileceğini açıklar.
Hash Tabloları her zaman en iyi çözüm değildir. Ek bellek kullanırlar ve doğal olarak sıralı düzeni korumazlar. Ancak, anahtar tabanlı hızlı erişim veya benzersizlik kontrolü gerektiğinde, mevcut en güçlü veri yapılarından biridirler.
Veri Yapıları ve Algoritmaları öğrenen geliştiriciler için Hash Tabloları hayati öneme sahiptir. Tekrar tespiti, sıklık sayma, önbellekleme, indeksleme, arama tabloları ve optimize edilmiş algoritma tasarımı dahil olmak üzere birçok pratik problemi verimli bir şekilde çözmek için temel oluştururlar.

